Classification de sons d'oiseaux, BirdCLEF+ 2026 (Kaggle)
Un pipeline de deep learning pour la reconnaissance multi-label d'espèces d'oiseaux à partir d'enregistrements sonores, …
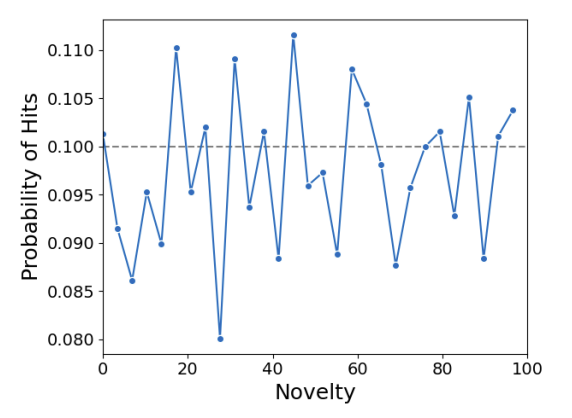
Ce projet de stage, réalisé au sein du laboratoire Bordeaux Sciences Économiques (Université de Bordeaux), s'inscrit dans la continuité d'un article publié en 2023 dans Nature Communications (Shi & Evans), qui propose une approche hypergraphique pour mesurer l'originalité des publications scientifiques et prédire leur impact. L'article original modélisait chaque publication comme un hyperedge reliant des nœuds de contenu (termes MeSH) et de contexte (revues citées), en apprenant les vecteurs d'embedding via une descente de gradient stochastique avec échantillonnage négatif. La propension d'une combinaison est calculée selon la formule $\lambda_h = \sum_d \prod_{i \in h} \theta_{id}$, et la nouveauté comme $\text{Novelty}(h) = -\log \lambda_h$. Les articles se situant dans le décile supérieur de nouveauté avaient jusqu'à 4× plus de chances d'être parmi les plus cités.
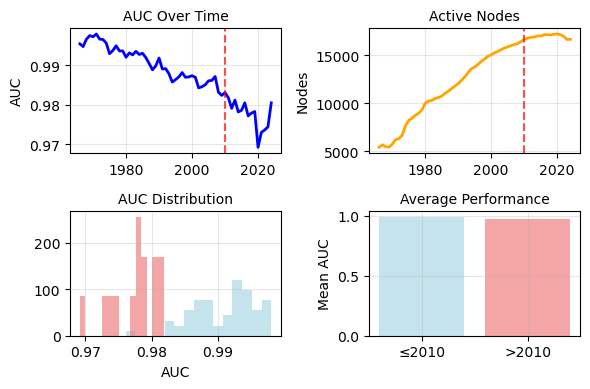
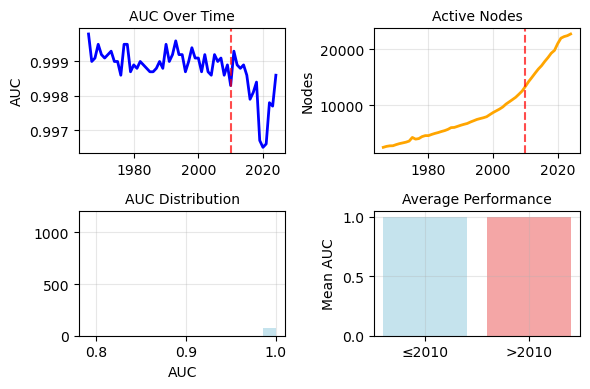
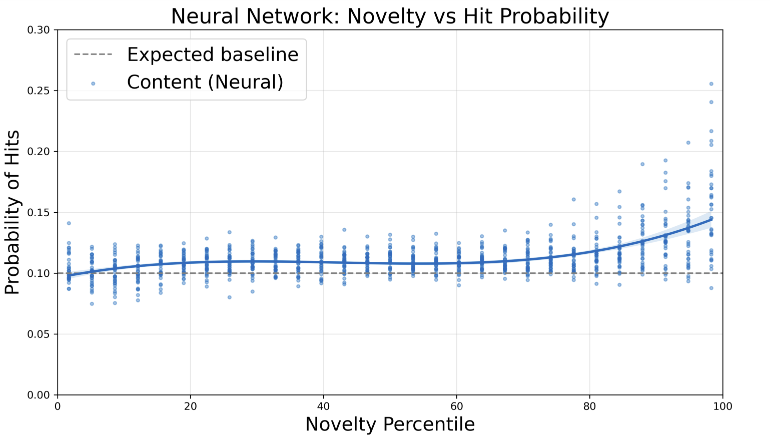
Le premier axe de ce stage a consisté en la reproduction fidèle du modèle sur notre infrastructure (adaptation CPU, conversion notebooks → scripts Python, documentation du code non commenté), suivie d'une extension de la période temporelle de 16,9 millions d'articles jusqu'en 2010 à 38,1 millions d'articles jusqu'en 2024. Les scores AUC obtenus sont de 0,97–0,99 pour le contenu et 0,997–0,999 pour le contexte, légèrement supérieurs aux résultats originaux. Pour l'hypergraphe de contexte, la base NIH-OCC (Open Citation Collection) a été intégrée pour porter la couverture des références de 50% à 76%, avec développement d'un système complet de normalisation des noms de journaux (800 millions de relations de citation traitées). L'analyse de corrélation avec les hit papers confirme les résultats originaux : nouveauté de contenu ×2, contexte ×4, effet combiné ×4,5.
Le deuxième axe visait à remplacer les termes MeSH par les mots-clés des auteurs pour étendre le modèle aux disciplines sans classification officielle. L'analyse de MEDLINE a révélé une couverture inférieure à 2% pour la période 1966–2012, rendant l'approche non viable. Face à cette limitation, le projet a été réorienté vers Web of Science et son système KeyWords Plus (50–60% de couverture depuis 1991, 3,4 millions de termes uniques). Pour réduire cette dimensionnalité, une architecture de clustering sémantique hiérarchique à deux niveaux a été développée : segmentation principale via MiniBatchKMeans (12 000–18 000 clusters), suivie d'un raffinement adaptatif basé sur le score de silhouette. Comparaison de BioBERT vs PubMedBERT pour le domaine biomédical (6 millions de mots-clés → ~21 000 clusters), puis adaptation avec SciBERT pour Web of Science. BioBERT s'est révélé supérieur sur toutes les métriques (Davies-Bouldin : 1,533 vs 1,619 ; Calinski-Harabasz : 5 727 vs 4 565).
Le troisième axe a consisté à développer un réseau de neurones fully-connected comme alternative au SGD, préservant les contraintes de normalisation ($\sum_d \theta_{id} = 1$) via softmax et sigmoïde, que les architectures Transformer ne peuvent pas respecter (ce qui expliquait leur échec dans l'article original malgré une AUC de 0,99). Notre modèle atteint 70% d'accuracy et maintient une corrélation positive avec les hit papers — contrairement aux Transformers. Cependant, le coût computationnel est prohibitif : 14 jours d'entraînement vs 7 heures pour SGD, pour des performances inférieures.
L'ensemble du traitement a nécessité jusqu'à 500 Go de RAM, certains scripts d'exécution continue de 2 semaines, et le traitement de 398 millions de références bibliographiques sur les serveurs Cremi et BSE.
Un pipeline de deep learning pour la reconnaissance multi-label d'espèces d'oiseaux à partir d'enregistrements sonores, …
Simulation et prédiction des communications dans un réseau P2P distribué avec déconnexions de nœuds, en …
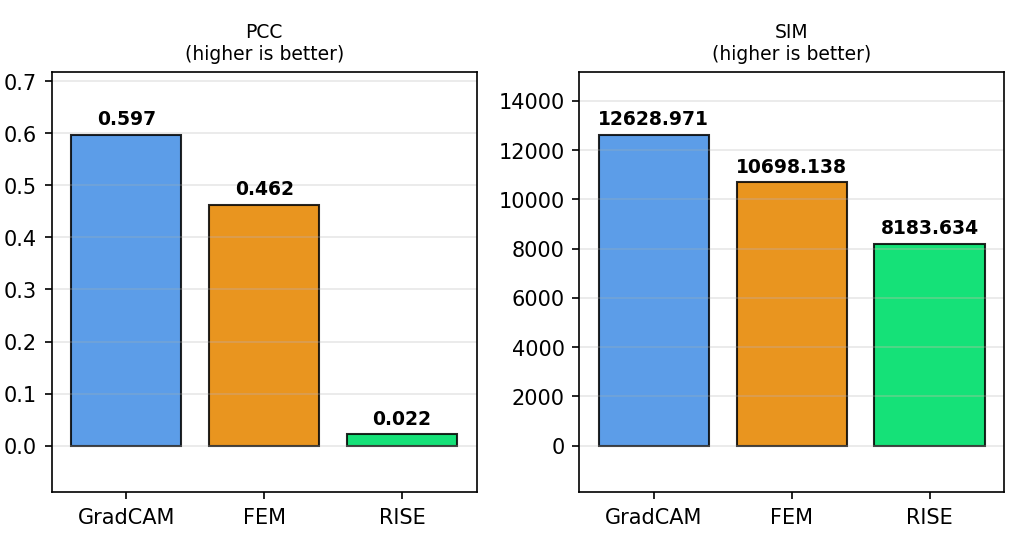
Comparaison de trois méthodes XAI (Grad-CAM vs FEM vs RISE) sur ResNet-18 à partir de …