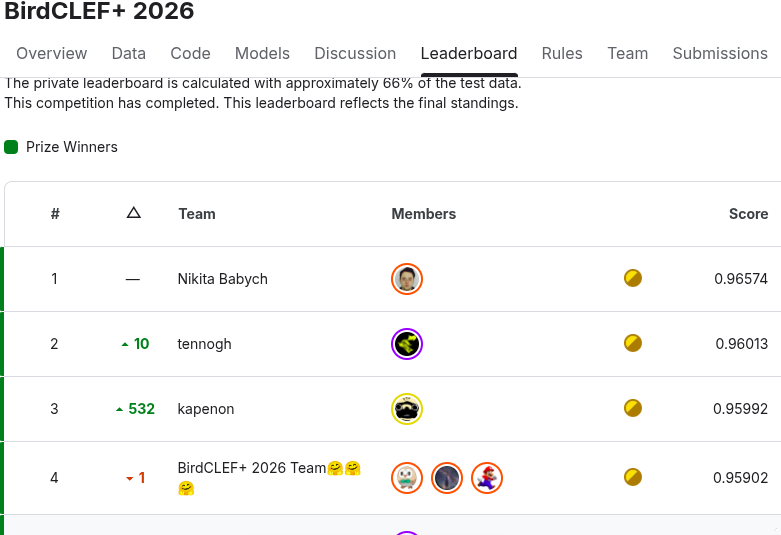
J'ai passé deux semaines sur la compétition Kaggle BirdCLEF+ 2026 : reconnaître 234 espèces d'oiseaux, d'amphibiens et d'insectes à partir d'audio de terrain bruité. J'ai terminé à 0,912 (classement privé). Le gagnant a atteint 0,96. Cet article parle de cet écart, non pas pour me plaindre, mais parce que l'écart lui-même a été la leçon la plus utile.
Le problème, en termes simples :
On s'entraîne sur des enregistrements propres (un oiseau, près du micro). Mais on est testé sur des paysages sonores de jungle denses et bruités, provenant d'un endroit différent. Le modèle doit généraliser malgré cet écart. De plus, les soumissions doivent s'exécuter uniquement sur CPU, en moins de 90 minutes : il est donc impossible de simplement utiliser un modèle géant.
Ce que j'ai construit :
Un mélange de deux modèles : le Perch v2 de Google (un modèle de fondation audio gelé, utilisé comme extracteur de caractéristiques) et un CNN EfficientNetV2-B0 personnalisé entraîné sur des mel-spectrogrammes, transformant chaque extrait de 5 secondes en une image et laissant le CNN reconnaître la signature visuelle de chaque espèce. Pour combattre l'écart de domaine, j'ai injecté des données de paysages sonores étiquetées dans l'entraînement via une validation croisée à 3 plis sans fuite. Cela m'a fait passer de la référence de 0,899 à 0,912.
Pourquoi le gagnant a atteint 0,96 :
J'ai lu attentivement le writeup de la 1ère place. La différence n'était pas « un meilleur code ». C'étaient des idées de ML plus profondes :
1. La distillation depuis Perch. Au lieu d'entraîner le CNN à partir de zéro, ils ont d'abord appris à leur modèle à imiter les représentations internes de Perch, puis l'ont affiné. Le CNN partait de connaissances, pas de zéro. C'est le plus grand levier qui m'a manqué.
2. Un ensemble diversifié, pas un seul modèle. Ils ont combiné environ 10 modèles avec des architectures différentes, des têtes de prédiction différentes (dont le SED, la détection d'événements sonores), et même des modèles spécialisés au niveau du genre et pour les amphibiens/insectes.
3. L'auto-apprentissage multi-itérations (Noisy Student). Ils ont utilisé les prédictions de leur propre modèle sur des données non étiquetées pour réentraîner, de manière itérative, passant de 0,935 à 0,95.
4. Une validation plus intelligente. Là où je m'appuyais sur un seul petit jeu de validation, ils ont conçu deux splits complémentaires pour mesurer honnêtement la généralisation.
5. Un mélange basé sur le rang, au lieu de moyenner les probabilités brutes.
La vraie leçon :
Le gagnant a dit quelque chose qui m'a marqué. Le travail sur Kaggle se divise en deux : la partie logicielle (écrire du code), que les outils d'IA automatisent maintenant très bien, et la partie DS/ML : générer de nouvelles idées, construire une intuition à partir de ses résultats. L'IA accélère la première. La seconde appartient encore à l'ingénieur humain.
C'est exactement là qu'était mon écart. Je n'ai pas perdu sur le code. J'ai perdu sur les idées de ML : distillation, auto-apprentissage, diversité d'ensemble. Cela vient de l'expérience et de la lecture, pas du fait de taper plus vite.
Voilà donc ma conclusion, et peut-être la vôtre si vous débutez : le goulot d'étranglement, ce ne sont pas les outils. C'est la profondeur. Lisez les writeups des gagnants. Comprenez pourquoi chaque décision a été prise. Construisez votre intuition. C'est la partie qui se capitalise.
0,912 n'est pas un trophée. Mais comprendre exactement pourquoi ce n'est pas 0,96, cela vaut plus que le classement.